6.14 Memory Options and Parallelization of Coupled-Cluster Calculations
The coupled-cluster suite of methods, which includes ground-state methods mentioned earlier in this Chapter and excited-state methods in the next Chapter, has been parallelized to take advantage of distributed memory and multi-core architectures. The code is parallelized at the level of the underlying tensor algebra library.[Epifanovsky et al.(2013a)Epifanovsky, Wormit, Kuś, Landau, Zuev, Khistyaev, Manohar, Kaliman, Dreuw, and Krylov]
6.14.1 Serial and Shared Memory Parallel Jobs
Parallelization on multiple CPUs or CPU cores is achieved by breaking down tensor operations into batches and running each batch in a separate thread. Because each thread occupies one CPU core entirely, the maximum number of threads must not exceed the total available number of CPU cores. If multiple computations are performed simultaneously, they together should not run more threads than available cores. For example, an eight-core node can accommodate one eight-thread calculation, two four-thread calculations, and so on.
The number of threads to be used in a calculation is specified as a command line option (-nt nthreads). Here nthreads should be given a positive integer value. If this option is not specified, the job will run in the serial mode.
Both CCMAN (old version of the couple-cluster codes) and CCMAN2 (default) have shared-memory parallel capabilities. However, they have different memory requirements as described below.
Setting the memory limit correctly is very important for attaining high performance when running large jobs. To roughly estimate the amount of memory required for a coupled-cluster calculation use the following formula:
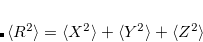 |
(6.46) |
If CCMAN2 is used and the calculation is based on a RHF reference, the amount of memory needed is a half of that given by the formula. If forces or excited states are calculated, the amount should be multiplied by a factor of two. Because the size of data increases steeply with the size of the molecule computed, both CCMAN and CCMAN2 are able to use disk space to supplement physical RAM if so required. The strategies of memory management in CCMAN and CCMAN2 slightly differ, and that should be taken into account when specifying memory-related keywords in the input file.
The MEM_STATIC keyword specifies the amount of memory in megabytes to be made available to routines that run prior to coupled-clusters calculations: Hartree-Fock and electronic repulsion integrals evaluation. A safe recommended value is 500 Mb. The value of MEM_STATIC should not exceed 2000 Mb even for very large jobs.
The memory limit for coupled-clusters calculations is set by CC_MEMORY. When running CCMAN, CC_MEMORY value is used as the recommended amount of memory, and the calculation can in fact use less or run over the limit. If the job is to run exclusively on a node, CC_MEMORY should be given 50% of all RAM. If the calculation runs out of memory, the amount of CC_MEMORY should be reduced forcing CCMAN to use memory-saving algorithms.
CCMAN2 uses a different strategy. It allocates the entire amount of RAM given by CC_MEMORY before the calculation and treats that as a strict memory limit. While that significantly improves the stability of larger jobs, it also requires the user to set the correct value of CC_MEMORY to ensure high performance. The default value is computed automatically based on the job size, but may not always be appropriate for large calculations, especially if the node has more resources available. When running CCMAN2 exclusively on a node, CC_MEMORY should be set to 75–80% of the total available RAM.
Note: When running small jobs, using too large CC_MEMORY in CCMAN2 is not recommended because Q-Chem will allocate more resources than needed for the calculation, which may affect other jobs that you may wish to run on the same node.
For large disk-based coupled cluster calculations it is recommended to use a new tensor contraction code available in CCMAN2 via libxm, which can significantly speed up calculations on Linux nodes. Use the CC_BACKEND variable to switch on libxm. The new algorithm represents tensor contractions as multiplications of large matrices, which are performed using efficient BLAS routines. Tensor data is stored on disk and is asynchronously prefetched to fast memory before evaluating contractions. The performance of the code is not affected by the amount of RAM after about 128 GB if fast disks (such as SAS array in RAID0) are available on the system.
6.14.2 Distributed Memory Parallel Jobs
CCMAN2 has capabilities to run ground and excited state energy and property calculations on computer clusters and supercomputers using the Cyclops Tensor Framework[Solomonik et al.(2014)Solomonik, Matthews, Hammond, Stanton, and Demmel] (CTF) as a computational back-end. To switch on the use of CTF, use the CC_BACKEND keyword. In addition, Q-Chem should be invoked with the -np nproc command line option to specify the number of processors for a distributed calculation as nproc. Consult Section 2.8 for more details about running Q-Chem in parallel.
6.14.3 Summary of Keywords
MEM_STATIC
Sets the memory for individual Fortran program modules
TYPE:
INTEGER
DEFAULT:
240
corresponding to 240 Mb or 12% of MEM_TOTAL
OPTIONS:
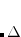
User-defined number of megabytes.
RECOMMENDATION:
For direct and semi-direct MP2 calculations, this must exceed OVN + requirements for AO integral evaluation (32–160 Mb). Up to 2000 Mb for large coupled-clusters calculations.
CC_MEMORY
Specifies the maximum size, in Mb, of the buffers for in-core storage of block-tensors in CCMAN and CCMAN2.
TYPE:
INTEGER
DEFAULT:
50% of MEM_TOTAL. If MEM_TOTAL is not set, use 1.5 Gb. A minimum of
192 Mb is hard-coded.
OPTIONS:
Integer number of Mb
RECOMMENDATION:
Larger values can give better I/O performance and are recommended for systems with large memory (add to your .qchemrc file. When running CCMAN2 exclusively on a node, CC_MEMORY should be set to 75–80% of the total available RAM. )
CC_BACKEND
Used to specify the computational back-end of CCMAN2.
TYPE:
STRING
DEFAULT:
VM
Default shared-memory disk-based back-end
OPTIONS:
XM
libxm shared-memory disk-based back-end
CTF
Distributed-memory back-end for MPI jobs
RECOMMENDATION:
Use XM for large jobs with limited memory or when the performance of the default disk-based back-end is not satisfactory, CTF for MPI jobs