A.7 GDIIS
Direct inversion in the iterative subspace (DIIS) was originally developed by Pulay for accelerating SCF convergence [242]. Subsequently, Csaszar and Pulay used a similar scheme for geometry optimization, which they termed GDIIS [899]. The method is somewhat different from the usual quasi-Newton type approach and is included in Optimize as an alternative to the EF algorithm. Tests indicate that its performance is similar to EF, at least for small systems; however there is rarely an advantage in using GDIIS in preference to EF.
In GDIIS, geometries 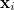 generated in previous optimization cycles are linearly combined to find the “best” geometry on the current cycle
generated in previous optimization cycles are linearly combined to find the “best” geometry on the current cycle
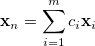 |
(A.33) |
where the problem is to find the best values for the coefficients 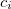 .
.
If we express each geometry, , by its deviation from the sought-after final geometry, 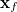 , i.e.,
, i.e., 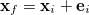 , where
, where 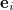 is an error vector, then it is obvious that if the conditions
is an error vector, then it is obvious that if the conditions
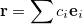 |
(A.34) |
and
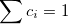 |
(A.35) |
are satisfied, then the relation
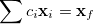 |
(A.36) |
also holds.
The true error vectors are, of course, unknown. However, in the case of a nearly quadratic energy function they can be approximated by
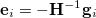 |
(A.37) |
where 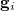 is the gradient vector corresponding to the geometry and
is the gradient vector corresponding to the geometry and  is an approximation to the Hessian matrix. Minimization of the norm of the residuum vector
is an approximation to the Hessian matrix. Minimization of the norm of the residuum vector  , Eq. (A.34), together with the constraint equation, Eq. (A.35), leads to a system of (
, Eq. (A.34), together with the constraint equation, Eq. (A.35), leads to a system of ( ) linear equations
) linear equations
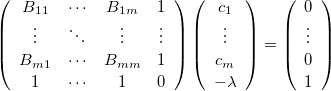 |
(A.38) |
where 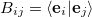 is the scalar product of the error vectors and
is the scalar product of the error vectors and 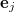 , and
, and 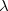 is a Lagrange multiplier.
is a Lagrange multiplier.
The coefficients determined from Eq. (A.38) are used to calculate an intermediate interpolated geometry
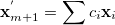 |
(A.39) |
and its corresponding interpolated gradient
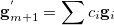 |
(A.40) |
A new, independent geometry is generated from the interpolated geometry and gradient according to
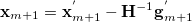 |
(A.41) |
Note: Convergence is theoretically guaranteed regardless of the quality of the Hessian matrix (as long as it is positive definite), and the original GDIIS algorithm used a static Hessian (i.e., the original starting Hessian, often a simple unit matrix, remained unchanged during the entire optimization). However, updating the Hessian at each cycle generally results in more rapid convergence, and this is the default in Optimize.
Other modifications to the original method include limiting the number of previous geometries used in Eq. eq:a23 and, subsequently, by neglecting earlier geometries, and eliminating any geometries more than a certain distance from the current geometry (default = 0.3 a.u.).